 There are two very different productivity ideas:
There are two very different productivity ideas:
- Make as much as you can! …meaning that:
- you are always busy (it is a ‘corporate crime’ to be idle!);
- it is irrelevant whether the next activity down the track is already snowed-under with work or even if it is available….you just keep pumping it out! They aren’t your problem;
- the ‘performance police’ are likely measuring the cost of the activity being performed, and judging you accordingly.
…this reflects a Push system, which fits with an ‘economies of scale’ efficiency mindset (“how many did you make!”).
- Make only what is needed when it is needed…meaning that:
- each person is highly connected to the next activity down the track (because they need visibility of how the next step is going);
- it becomes immediately obvious if there is a blockage and where it is;
- the process performers can:
- collaborate on making improvements at the (now visible) bottlenecks; and
- see and measure the overall flow, from customer demand through to its satisfaction.
…this reflects a Pull system, which fits with a ‘flow’ effectiveness mindset (“how did we all do together for the customer?”)
Now, you might think that push will cost a lot less than pull because everyone is always working flat out, not waiting to do something….but you’d probably be wrong, and by a profound margin.
What’s so good about pull?
Here’s a simple ‘push’ diagram from the Lean Enterprise Institute to assist:
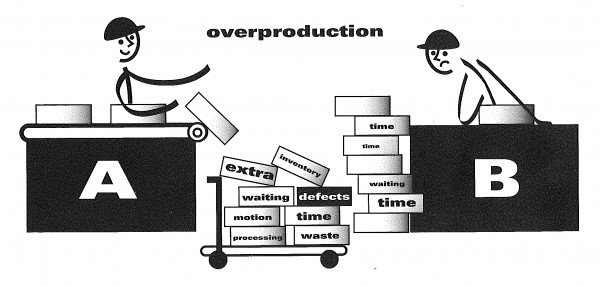
Stick man ‘A’ is happily making stuff, much to the despair of ‘B’ and, given that a real life process will have far more steps than A and B, you can imagine what this looks and feels like on a bigger scale – organised(?) chaos:
- work will pile up throughout the process, meaning that there will be loads of ‘work in process’;
- process steps might be working flat out, but it takes a really long (and usually increasing) time for a unit of work to get from start to (proper) completion. It spends a massive amount of its overall cycle time simply waiting;
- defects are hidden within this mess, so it takes a long time for them to surface….with the time and cost to rectify the defect rising alarmingly as more work is performed on the defective unit of work;
- changes in specifications or customer needs whilst units are (a long time) in process mean a huge amount of rework, and even scrapping of work done to date (Customer: “In the time you’ve taken, things have changed….I don’t want that anymore!”);
- the long cycle times will create a huge amount of failure demand (blue marbles) from customers asking where their unit of value demand has got to and how long it will be.
Is this relevant to Service?
Absolutely! But, like most things, it can be a bit different to manufacturing.
THE big difference in service is that the trigger to start work is pull by default i.e. you can’t make a service in advance ‘and put it into stock’…you need to wait for demand to trigger the work. But, just because we have a customer pulling the demand lever doesn’t mean we should then be pushing their unit along a value stream before the downstream activities are ready for them.
For a really obvious example, let’s take a natural catastrophe (flood, earthquake, etc.), which results in an insurer getting a huge spike of claims demand. The insurer wants to help everyone as soon as they can but they a) are still getting the necessary processes defined ‘on the ground’ and b) have limited resources to do the work.
Now, this is a challenge: Insurers want to be seen to be pro-active and ‘getting on with it’ for their customers. But beware of creating a seemingly good short-term impression at the expense of a huge longer-term mess.
If you push claims through a process that isn’t yet defined and resourced then you can expect to:
- only partially perform the necessary work, but not realise this;
- set expectations that turn out to be incorrect (e.g. what you thought looked clearly a house rebuild turns out later to only be a repair…and vice versa);
- go back and perform a great deal of re-work (ending up in multiple site visits, ‘reconciliations’ with previous findings, defensive explanations and compensatory actions);
- throw away old work and virtually start again to cope with changing customer circumstances (“I was okay with you doing that 6 months ago…but not anymore”); and
- lose the trust of the customer (your unintended mistakes are seen by them as malice and trickery)…which creates much failure demand, to be cautiously tip-toed through.
If you hear management say “right, let’s get all the claims through ‘assessment’ by [date x] and then we’ll focus on the next stage”, you know you’ve got push and all its associated problems.
This doesn’t mean that you don’t do all you can to make sure your customer is okay whilst you work things out (e.g. temporary repairs, emergency accommodation) and explain to them what is happening (including what you haven’t got in place yet)…but it is saying pull work through your flow when, and only when, you (& they) are ready for it.
This means that you focus your attention on defining and refining the flow, rather than wasting it firefighting each and every ‘undoing what’s already been done’ disaster.
A specific example for the catastrophe claims scenario: If a builder has a number of house builds on the go, don’t push any more on them (they may very well tell you they can take them!). Instead, allow them to pull the next one only as and when each build is satisfactorily complete. This will mean that the builder is focused on making their build processes effective, rather than trying to stockpile work for the next few years.
Moving on to ‘workflow management’:
Okay, so thankfully catastrophe management doesn’t happen all the time…so what about ‘day to day’ pull in service?
Who works in an area that has a ‘workflow management’ role (or even team) that sorts out work as it comes in the door by briefly looking at what it is, categorising it and then assigning it to people as fairly as they can? This is pushing.
What does this cause?
- Incorrect classification: As explained in ‘The Spice of Life’, there is huge variation in service demand. It is impossible to properly appreciate the necessary work content until you do the work; which means that…
- Feelings of unfairness: …it is impossible to fairly divide up the work. This wouldn’t be such a problem if judgement and rewards weren’t hanging on it…but they usually are! This creates a constant tension between the work assigner and the workers; leading to…
- Dysfunctional behaviour: …people will do what they can to protect themselves. You can read ‘The trouble with targets’ to see the general techniques that people understandably use to survive;
- Re-working the workflow: So the work has been carefully assigned for the week ahead but Jack’s work is turning out to be slower than expected (Bob’s is easier than expected but he isn’t going to tell you!), and Jill is off sick…this only comes to light mid-way through the week so customers in Jack and Jill’s trays have been waiting in vain. Push requires a constant need to review and re-sort allocations between queues as circumstances (always) change…which is pure waste.
What’s wrong with people pulling work from a central and highly visible ‘pile’?
‘Command & Control’ Manager: “Well, people can’t be trusted to do this can they!”
Counsel: “Eh? Why ever not?!”
Manager: “Well, they will slow down and look for the easy ones.”
Counsel: “and why would they do that?
Manager: “Erm, because of their personal metrics…needed because their performance is being judged…which will affect their linked rewards/awards.”
I hope you can see that this is a classic case of looking past a logical tool/technique (in this case ‘pulling work’) and seeing the root causes within the ‘command and control’ management thinking.
If the team:
- had a capability measure as to how they are all doing (so that they could see the system, rather than being blinded by personal targets);
- were being coached, not judged (so that they wanted to improve, not protect, themselves;) and
- were sharing in their success (so that they wanted to collaborate, not compete)
…then a) designing an initial* pull system could deliver great results and b) the workers would likely look for, and make, continual improvements to it…so that it worked better and better and better.
* don’t try to implement the perfect pull system: let the workers move towards pull through experimentation….but management must remove the constraints that are in their way.
Examples of service moving from push to pull:
In fact we have all felt moves from push to pull. One obvious area has been customers (that’s us) being able to book appointments (pull) rather than being assigned a slot (push). This has happened from medical appointments, through school parent evenings, to home deliveries.
Note that ‘pull’ is actually an ideal, not a tool. You need to think widely (and differently) about achieving it. It isn’t an easy journey…but it’s well worth the effort.
How about this one from John Seddon: When a contact centre agent gets a customer demand that they are unfamiliar with, they should ‘pull’ in the necessary expertise to handle it, instead of ‘pushing it’ to the expert to perform. In this way, the agent is developing on the job and the customer feels that one person is caring for/ owning their need…developing great trust: a win/win.
Pulling is linked with continuous improvement, like an umbilical cord.
Notes:
- Pull is a key part of the Toyota Production System (TPS), and is the 4th of the 5 ‘Lean Thinking’ principles;
- Kanban is a Japanese word and refers to a visual signal (often a card) used to trigger an action. The downstream process provides the kanban (signal) to the upstream process (i.e. it pulls the work along the value stream).
- You can substitute the catastrophe example used above with any service process where a) the process isn’t yet properly defined and/ or b) a spike in demand has to be handled (i.e. exceeds capacity)
